
C++记忆恢复集要之三:继承、多态与容器
继承
类是C++封装特点的重要体现,类的继承是指从已有的基类(父类)派生出的新类(子类),是C++面向对象的第二个重要特点。类的继承写法如下:
1
2
3
4
5
6
7
8//单类继承
class 子类类名:继承类型 父类类名{
...
};
//多类继承
class 子类类名:继承类型 父类类名,继承类型 父类类名...{
...
};
1. 三种继承类型
三种继承类型:公有继承(public)
、私有继承(private)、受保护继承(protected)。
子类并不是照搬父类的成员权限,而是根据继承类型和父类的类内权限共同决定的。总结如下:
1.
父类私有权限成员:无论以何种方式继承,子类和类外均不能直接访问和操作(私有成员变量的确占用了子类的空间,但是这些变量对子类是不可见的,既然是不可见,就说不上在子类中有什么权限,所以一般要通过父类的公有函数来访问);
2.
父类受保护权限成员:公有、受保护继承时,该成员在子类权限仍为受保护权限,私有继承时在子类权限为私有权限;
3.
父类公有权限成员:公有继承时,在子类权限为公有权限;受保护继承时,在子类权限为受保护权限;私有继承时,在子类权限为私有权限。
2. 父类函数的继承与调用
2.1 继承
子类可以继承父类大多数的成员函数,但有几种函数是没有继承的,如父类的构造函数、析构函数、友元函数、等于号的运算符重载函数等,但是子类的实例化会触发父类构造、析构函数的调用。
2.2 调用顺序
子类的实例化会先调用父类的构造函数,再调用子类的构造函数,销毁时先调用子类的析构函数,最后调用父类的析构函数。如果考虑类成员对象,则调用构造函数的完整顺序为:
1
父类成员对象构造函数->父类构造函数->子类成员对象构造函数->子类构造函数
2.3 调用细节
子类不继承父类构造函数,子类实例化形式必须和子类本身构造函数形式一致才能初始化成功。例如,只有父类仅设置了有参构造,子类没有手动设置构造函数,则不能正常实例化。
调用父类构造函数时,尽管变量、函数形式与父类有参构造函数对应,默认调用的也是父类的无参构造函数;
主动触发父类有参构造的方法:链表传参
1 | //子类有参函数采用链表触发父类的有参构造 |
链式继承:即爷到父,父到子,重复命名成员变量,调用有参构造时,参数数量逐代递增,如爷类(这应该不是严格的术语)需要1个形参,父类需要2个(其中一个链式传参给爷类),子类需要三个(其中两个链式传参给父类)。
扇形继承:即子类同时继承父类和母类(非术语,形象表述),调用有参构造时,子类链式传参一个供给父类、一个供给母类即可。
菱形继承:在扇形继承的上一代,父类、母类又继承同一个类(假设为爷类)。这时如果考虑逐代继承子类将有5个同名成员变量,事实上很少会遇到这种情况。反而应该考虑的是当只有爷类的成员变量时,却因为父类、母类等多类继承存在,增加了变量的指向,导致二义性,如果总是通过指定父类、母类来操作爷类的变量显然是不够合理的。这种情况下,父类、母类往往采用虚继承的方法,用virtual修饰写法:
这种继承方式子类除了继承父类成员和指针(该指针本身指向父类成员地址),还会多一个指针(虚基表指针)指向一个虚基表,记录了虚父类与本类的偏移,通过这个偏移可以找到虚父类的成员。此时子类完全可以使用成员访问符号(.)访问爷类的成员,而不会与父类、母类混淆产生二义性,虚继承也是一种动态多态思想。1
2
3
4
5
6
7class Father:virtual public Grandpa{...};
class Mother:virtual public Grandpa{...};
class Grandson : public Father, public Mother{...};
Grandson.data = xxx; //访问爷类变量(虚基类),孙类(派生类)直接访问虚基类成员
Father::data_Parent = xxx; //父类、母类存在同名变量,要指定域
Mother::data_Parent = xxx;
以下学完多态再回头看:虚继承+虚函数重写。
虚继承不能解决虚函数重写的问题,例如菱形虚继承,孙类(派生类)最后的虚函数表函数指针不是完全来自爷类(虚基类),而是会来自两个父类,意味着如果两个父类重写了虚函数,而孙类自己不重写,继承时应该定义一个。
1
2
3void foo() override{
Father::foo();
}
3. 继承成员变量
子类可以按规则继承父类的成员变量,而且支持同名成员变量同时存在,默认情况下访问的是子类特有的成员变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14class IamParent{
public:
string name;
};
class IamSon:public IamParent{
public:
string name; //同名
};
int main{
IamSon S1;
S1.name="xxx"; //默认子类
S1.IamParent::name="xxx";//类名域解析符调用父类变量
return 0;
}
多态
多态是面向对象程序设计数据抽象、继承以外的第三个基本特征。多态提供接口与具体实现之间的另一层隔离,改善了代码的可读性和组织性,也使创建的程序具有可扩展性。C++支持编译时多态(静态多态)和运行时多态(动态多态),静态多态是在编译阶段确定了函数调用地址并且产生代码,如函数重载、运算符重载等,而动态多态的函数地址在运行时才确定,如虚函数、纯虚函数、虚析构函数、纯虚析构函数。
1. 动态多态
1.1 虚函数
运行时确定编址
一般而言,每个函数定义完成后在编译阶段就确定了函数的调用地址,当运行时直接调用即可,而虚函数则是编译时不确定要调用的函数地址,在函数运行时才根据保存的地址来调用函数。以下是一个简单的例子来体会虚函数的作用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
class Parent_Coach{
public:
void CountNum(){
cout<<"I am coach!"<<endl;
}
};
class No1_player:public Parent_Coach{
public:
void CountNum(){
cout<<"I am No.1 player!"<<endl;
}
};
class No2_player:public Parent_Coach{
public:
void CountNum(){
cout<<"I am No.2 player!"<<endl;
}
};
class No3_player:public Parent_Coach{
public:
void CountNum(){
cout<<"I am No.3 player!"<<endl;
}
};
int main(){
//父类指针尝试调用子类函数方式
//非虚函数效果
Parent_Coach *C1=new No1_player;
C1->CountNum();
Parent_Coach *C2=new No2_player;
C2->CountNum();
Parent_Coach *C3=new No3_player;
C3->CountNum();
return 0;
}1
2
3
4
5
6
7class Parent_Coach{
public:
//父类设置为虚函数,子类的同名函数也会对应变成虚函数,无需重复设置
virtual void CountNum(){
cout<<"I am coach!"<<endl;
}
};
!!一定注意:虽然只给父类的CountNum赋予虚函数特性,子类此时同名函数也是虚函数。
结果:I am No.1 player! I am No.2 player! I am No.3 player!
结合上面分析不难知道结果原因,编译时父类函数地址没有生效,虚函数在运行时才确定调用函数地址为新开辟的子类空间函数地址。这种方法的好处当有多个子类时无需一一实例化去调用,父类指针可以方便完成。
虚函数表指针与虚函数表
计算一个普通空类/带成员函数: 1
2
3
4
5
6
7class Test{
public:
void func(){};
};
Test myTest;
cout<<sizeof(myTest);
另一方面,如果定义:virtual void func(){};,这时计算类的大小,在Visual
Studio中占4字节,在64位gcc编译器上占8字节。这时实际上隐性地产生了一个虚函数表指针void *vptr指向虚函数表,虚函数表内是本类的虚函数指针地址。
如果发生继承,子类会同样继承这个虚函数表,如果子类对同名虚函数进行重写,那么表内的虚函数指针会被子类的虚函数覆写,最后产生多态效果。
应用场景
最重要的应用场景是,父类可以实现笼统的函数作为框架函数,然后定义一些虚函数,这样父类指针去new一个子类对象,或者父类引用绑定一个子类对象时,父类对象调用/子类实例化调用,都能够执行子类自己定义的虚函数,实现个性化功能。
如果父类不定义某个函数的默认行为/参数,一定通过子类去自定义功能,那么就是纯虚函数的使用。
总的而言,虚函数多态,就是父类对象绑定不同的子类虚函数,实现自定义功能;或者说子类对象,去使用父类的框架,某些函数内能够实现自定义的功能。
1.2. 纯虚函数
与虚函数相比,纯虚函数没有函数体,不能进行实例化操作,只作为父类,子类要去重写(override)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
using namespace std;
class Parent_Coach{
public:
virtual void CountNum()=0; //父类函数没有函数体,=0也同时声明了这是一个抽象类,不能实例化
};
class No1_player:public Parent_Coach{
public:
void CountNum(){
cout<<"I am No.1 player!"<<endl;
}
};
class No2_player:public Parent_Coach{
public:
void CountNum(){
cout<<"I am No.2 player!"<<endl;
}
};
class No3_player:public Parent_Coach{
public:
void CountNum(){
cout<<"I am No.3 player!"<<endl;
}
};
//父类虚函数,指针作为形参
int printInfo(Parent_Coach *p){
p->CountNum();
}
int main(){
//实例化子类传入子类地址
No1_player N1;
printInfo(&N1);//小指针大内存,上行转换是安全的
No2_player N2;
printInfo(&N2);
No3_player N3;
printInfo(&N3);
return 0;
}
1.3. 虚析构函数
用父类指针保存子类地址,一个很大的特点是不会调用子类的析构函数,这在一般情况是无关紧要的,但是如果子类额外开辟了动态空间(例如指针变量),这样堆区的空间就没有被释放,因此要通过虚析构函数解决,父类定义了虚析构函数,子类的析构函数也是虚函数,这样父类对象的析构也会调用子类析构,释放堆区空间,防止内存泄漏。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
using namespace std;
class Parent{
public:
Parent(){
string name="";
score=0;
cout<<"This is Parent non-parameter constructor"<<endl;
}
Parent(string name,int score):
name(name),score(score)
{
cout<<"This is Parent parameter constructor"<<endl;
}
virtual ~Parent(){ //父类设置虚析构,子类也是虚析构,无需重复设置
cout<<"This is Parent destructor"<<endl;
}
string name;
int score;
};
class Son:public Parent{
public:
Son(){
name="";
score=0;
id=NULL;
cout<<"This is Son non-parameter constructor"<<endl;
}
Son(string name,int score,char *id):Parent(name,score)
{
this->name=name;
this->score=score;
this->id=new char[strlen(id)+1];
strcpy(this->id,id);
cout<<"This is Son parameter constructor"<<endl;
}
~Son(){
if(id!=NULL){
delete []id;
cout<<"This is Son destructor"<<endl;
}
}
char *id;
};
int main(){
//Son S1("Eden",100,"FBI"); //一般实例化方法,子类能正常析构
Parent *p=new Son("Eden",100,"FBI");//父类指针调用子类成员或函数
cout<<p->name<<endl;
delete p; //手动释放父类父类指针,若没有虚析构则不会释放子类堆区的char* id
return 0;
}1
2
3
4
5
6
7class Parent{...
virtual ~Parent()=0; //父类设置纯虚析构
...};
//类外实现
Parent::~Parent(){ //父类设置虚析构
cout<<"This is Parent destructor"<<endl;
}
2. 函数模板和类模板
2.1. 函数模板
函数模板实际上是更强大的函数重载,在用户编写代码参数时可以不直接指定参数类型;改用typename或class修饰声明即可,如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
using namespace std;
template<typename type> //同类相加
void addnum1(type num1,type num2){
cout<<num1+num2<<endl;
}
//模板也支持重载,异类相加
template<class type1,class type2>
void addnum1(type1 num1,type2 num2){
cout<<num1+num2<<endl;
}
int main(){
//隐式调用
//同类test
addnum1(1,3);
addnum1('a','b'); //ASCII值相加
//异类test
addnum1(1,1.513);
addnum1('a',12.21);
//显式调用,int是指定参数的数据类型,不是结果数据类型
addnum1<int>(1,5); //不指定可省略int
return 0;
}
2.2 类模板
在类中也可以不指定成员变量、成员函数的参数类型,其模板格式、函数调用与普通函数略有不同。如:
1. 类模板中函数调用必须采用显式调用方式指定数据类型,不能采用隐式调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
template<typename type1,typename type2>
class Person{
public:
//有参构造
Person(type1 name,type2 score):
name(name),score(score)
{
cout<<"This is Parent parameter constructor"<<endl;
}
type1 name;
type2 score;
};
int main(){
//类模板的函数调用务必指定参数类型,即要显式调用
Person <string,int>Eden("Mike",100);
return 0;
}1
2
3
4
5//函数类外实现写法
template<typename type1,typename type2>
void Person<type1,type2>::printInfo(){
cout<<name<<'/t'<<score<<endl;
}1
2
3
4
5
6
7
8
9
10
11//类内函数声明:
template<typename t1,typename t2>
void changeInfo(t1 name,t2 score);
...
//类外实现
template<typename type1,typename type2>
template<typename t1,typename t2>
void Person<type1,type2>::changeInfo(t1 name,t2 score){
this->name=name;
this->score=score;
}
- 子类继承父类类模板并实例化,存在三种情况:
A. 子类本身可确认参数类型,无需使用类模板:B. 子类不确认函数参数,实例化时才指定;1
2
3
4
5
6
7
8
9
10
11
12//指定参数类型的子类继承
class Son1_Person:public Person<string,int>{
public:
Son1_Person(string name,int score){
this->name=name;
this->score=score;
cout<<"This is Son parameter constructor"<<endl;
}
};
...
//实例化时正常实例化即可,无需重新确认参数
Son1_Person Eden_Son("Lucy",99);1
2
3
4
5
6
7
8
9
10
11
12
13//子类仍要继承父类类模板且不指定参数类型
template<typename type1,typename type2>
class Son1_Person:public Person<type1,type2>{
public:
Son1_Person(type1 name,type2 score){
this->name=name;
this->score=score;
cout<<"This is Son parameter constructor"<<endl;
}
};
...
//实例化时指定参数类型
Son1_Person <string,int>Eden_Son("Lucy",99);
C.
子类除了继承父类类模板,自身还有其他类模板参数,和父类一起声明函数模板,而不是分段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17template<typename type1,typename type2,typename type3,typename type4>
class Son1_Person:public Person<type1,type2>{
public:
Son1_Person(type1 name,type2 score,type3 id,type4 address){
this->name=name;
this->score=score;
this->id=id;
this->address=address;
cout<<"This is Son parameter constructor"<<endl;
}
//子类新增的类模板参数
type3 id;
type4 address;
};
...
//实例化时声明所有模板类型
Son1_Person <string,int,int,string>Eden_Son("Lucy",99,1,"University");
异常处理机制
用户自定义机制
C语言处理程序错误,常常是返回一个指定值来标识错误,或者直接杀死这个进程,显然这种方法是不够成熟的,因为指定值可能引起多义性,进程结束了也无法执行后续的代码。C++中则提供了一套异常处理机制,在不结束程序的前提下,也能进行相应的处理,主要是通过故障检测(try语句块)、抛出错误(throw关键字)、处理错误(catch函数)来实现。一个检查除数是否为0的简单例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
using namespace std;
//封装函数时定义错误代码
int divtest(int a,int b){
if(b==0){
throw -1;} //throw对象可以是常量,也可以是函数,当遇到throw会立刻停止执行try语句,执行catch语句
else{
return a/b;
}
}
int main(){
//调用函数时try放可能出错的函数
try{
cout<<divtest(100,5)<<endl;
}
//catch函数必须紧跟try语句块,中间不能有其他代码
catch(int &e){ //参数必须和扔出的代码类型一致,且一般为引用格式,catch函数可以根据抛出数据类型不同而实现重载
cout<<"Wrong Operation"<<endl;
}
return 0;
}
标准异常库
标准库提供了很多异常类,通过类继承组织而来,层级结构如下:(图自CSDN)
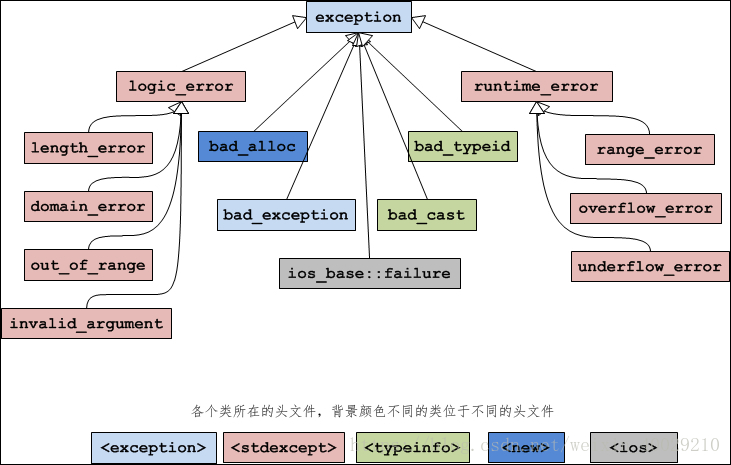 每个类的颜色对应了下面五个头文件,一般使用exception即可。
每个类的颜色对应了下面五个头文件,一般使用exception即可。
标准异常类中: 1. 每个类都提供了构造函数、复制构造函数和赋值操作符重载;
2.
logic_error、runtime_error类及其子类的构造函数都接受一个string类型的形式参数,用于异常信息描述;
3. 所有函数都有一个what()函数,返回字符串类型const
char*类型信息,描述异常现象。
常用的标准异常类描述(摘自CSDN:异常处理)
- std::bad_alloc: 当无法分配内存时,会抛出此异常;
- std::bad_cast: 当进行类型转换时,如果转换失败,会抛出此异常;
- std::bad_exception: 当异常处理程序无法处理异常时,会抛出此异常;
- std::logic_error: 当程序中出现逻辑错误时,会抛出此异常;
- std::out_of_range: 当访问超出有效范围的数组元素、vector 或 string 时,会抛出此异常;
- std::length_error: 当试图创建一个超过可表示长度的容器时,会抛出此异常;
- std::domain_error: 当计算一个数学函数的结果时,如果结果不在定义域内,会抛出此异常;
- std::invalid_argument: 当一个函数接收到无效的参数时,会抛出此异常;
- std::runtime_error: 当程序运行时发生错误时,会抛出此异常;
- std::overflow_error: 当整数运算结果太大,无法表示时,会抛出此异常;
- std::range_error: 当数学函数的结果是无限大或 NaN 时,会抛出此异常;
- std::underflow_error: 当数值下溢,即数值太小而无法表示时,会抛出此异常;
- std::system_error: 当系统调用失败时,会抛出此异常;
- std::system_fault: 这是一个用于指示由操作系统引起的错误的异常类;
- std::bad_typeid: 当试图对一个对象使用 typeid 运算符,而该对象没有定义 typeid 时,会抛出此异常;
- std::bad_weak_ptr: 当使用无效的弱指针时,会抛出此异常;
- std::exception_ptr: 这是一个可以持有异常对象的指针类型;
- std::future_error: 当 future 对象的结果未能按预期准备就绪时,会抛出此异常;
- std::invalid_promise: 当 future 对象接收到无效的 promise 时,会抛出此异常;
- std::lock_error: 当尝试锁定一个已经被锁定的互斥量(mutex)时,或者当尝试解锁一个未被锁定的互斥量时,会抛出此异常;
- std::mutex_consistent_set: 当使用std::set_lock_state 设置一个互斥量的状态时,如果该状态无效,会抛出此异常;
- std::deadlock: 当在两个或更多的线程间产生死锁时,会抛出此异常;
- std::unexpected: 当未捕获处理函数中抛出的异常时,会抛出此异常;
示例代码:数组越界异常处理
1 |
|
标准模板库STL
Standard Template
Library是惠普实验室开发的一系列软件,主要出现在C++中,但STL诞生于引入C++之前,目的是建立一套数据结构和算法标准,以基于此增加代码的复用性,减少复杂且重复的工作。
STL从广义上分为容器(container)、算法(algorithm)、迭代器(iterator),容器、算通过迭代器无缝连接。例如不同数据结构(如链表、顺序表)的删除算法应该是有所不同的,但都可以通过迭代器的代码却几乎一样。
STL参考网址:https://cplusplus.com/,搜索对应容器即可。
STL六大组件
这六大组件分别是:
- 容器:各种数据结构,如vector、list、deque、set、map等,用于存放数据,从实现角度看,STL容器是一种类模板。
- 算法:各种常用算法,如sort、find、copy、for_each,从实现角度看STL算法是一种函数模板。
- 迭代器:是容器算法之间的粘合剂,共有输入、输出、前向、双向、随机访问五种类型;从实现角度看,迭代器是一种将operator*、operator->、operator++、operator--等指针相关操作予以重载的类模板,所有STL容器都有自己专属的迭代器,只有容器设计者才知道如何遍历自己的元素,原生指针(native
pointer)也是一种迭代器。
- 仿函数:行为类似函数,可作为算法的某种策略,就像是自定义的魔法咒语,可以根据自己的需要来定义处理数据的方式。仿函数可以作为算法的参数,用于自定义排序、查找等操作的方式。从实现角度来看,仿函数是一种重载了operator()的类或类模板。
C++仿函数是一种在类或者结构体中定义的函数,通常通过重载括号运算符(operator())实现的,重载函数支持函数重载,定义不同的参数数量、参数类型、返回数据类型等,仿函数本身是一种类对象,程序运行时能够保持变量状态,就像全局变量和静态变量一样,且性能上仿函数能够被编译器优化,性能较好,下面是一个保持变量状态的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// 仿函数类,用来累计一个数值
class Accumulator {
private:
int sum;
public:
// 构造器初始化成员变量
Accumulator() : sum(0) {}
// 重载括号操作符,使其可以累加传入的值并返回累加的结果
int operator()(int number) {
sum += number;
return sum; // 返回累加后的结果
}
// 这可以用来在任何时候获取当前的累计总和
int getSum() const {
return sum;
}
};
int main() {
Accumulator acc; // 创建一个累加器对象
std::cout << "Adding 5: " << acc(5) << std::endl; // 输出: Adding 5: 5
std::cout << "Adding 10: " << acc(10) << std::endl; // 输出: Adding 10: 15
std::cout << "Adding 6: " << acc(6) << std::endl; // 输出: Adding 6: 21
// 此时累加器中的 sum 成员变量保存了累加的状态,即 21
std::cout << "Current sum: " << acc.getSum() << std::endl; // 输出: Current sum: 21
return 0;
}
- 适配器(配接器):一种用来修饰容器或者仿函数或迭代器接口的东西,就像是盒子的改装工,可以修改容器、仿函数或迭代器的接口,以适应不同的需求。适配器可以让我们使用不同的方式来操作数据。
- 空间配置器:负责空间的配置与管理,从实现的角度看,配置器是一个实现了动态空间配置、空间管理、空间释放的类模板。
常用容器
string容器
1. 构造函数
1 |
|
2. 赋值操作
1 |
|
3. 索引取值操作
[]运算符重载函数与at()函数都能获取某个索引值的字符,其中[]不具有异常处理机制,而at函数有
1
2
3
4
5
6
char& operator[](int n);
char& at(int n);
s1[index];
s1.at(index);
4. 拼接操作
1 |
|
5. 查找操作
1 |
|
6. 字符串比较
1 |
|
7.string子串
1 |
|
8. string插入和删除操作
1 |
|
代码实战:string成员函数实现strtok函数功能
strtok函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
char* strtok(char *str,const char *delim);
功能:进行字符串切割
参数:
str:当前要切割的字符串
delim:根据指定字符串切割
返回值:
成功:切割出来的字符串
失败:NULL
切割完毕:NULL
如果需要对同一个字符串反复切割,则只需要把第一个参数置为NULL即可。
//test code
using namespace std;
int main(){
char s[]="EdenMo,man,China";
char *p=strtok(s,",");
cout<<p<<endl;//EdenMo
while(p!=NULL){
p=strtok(NULL,",");
cout<<p<<endl;
}
//EdenMo man China
}string类成员函数方法 循环思想:获取索引值——分割子串——更新获取索引值——分割,当索引值为npos或-1(二者等效),跳出循环。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
using namespace std;
void My_strtok(string& str,string flag){
size_t index=str.find(flag);
int n=0;
while(index!=string::npos){
cout<<str.substr(n,index-n)<<endl;
n=index+1;
index=str.find(flag,index+1);
}
cout<<str.substr(n,str.size()-n)<<endl;
}
int main(){
string str="EdenMo,man,China";
My_strtok(str,",");
return 0;
}
string内存管理策略
string实例化对象时,会开辟一个合适大的空间以容纳对象,但当对象长度发生过分变化时,string有可能会释放原来空间,而新开辟一块地址存储新的对象。因此不应该事先保存string中字符的指针或者引用进行操作,因为可能在未察觉间地址已经释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
using namespace std;
int main(){
string s1("Hello World");
cout<<s1<<'\t'<<"capacity:"<<s1.capacity()<<endl;
printf("%p\n",&s1[0]);
s1="sdjaljflfjlsfjlhkhjkhkhkhksdjf";
cout<<s1<<'\t'<<"capacity:"<<s1.capacity()<<endl;
printf("%p\n",&s1[0]);
return 0;
}
可见string指向首字符地址已经改变,因为s1[0]是一个重载中括号函数,返回值是字符的引用即char &c,因此如果事先保存了这个字符,当字符串变化时这样写就失效了,而不会寻回新地址对应索引值字符。注意这里不是&s1,s1是一个类对象,存放在栈区,改变字符串不会影响它的栈区的地址。
vector容器
vector的数据安排以及操作方式,和数组(array)非常相似,两者的唯一差别在于空间的灵活性,array是一个静态空间,一旦配置了大小就不能改变,需要更大的空间就必须开辟一块新的空间并且把旧元素拷贝过去,释放原来的空间。vector是动态的空间,随着元素的加入,它的内部机制会自动扩充空间以容纳新的元素,这样避免了使用array时一开始就创建一块极大的数组空间。其次,vector是一种类似单端数组的结构,有尾部插入和删除的功能,也提供了任意位置插入、删除功能(通过类似指针的迭代器实现),因此不能把vector看成栈结构。
1. vector的空间申请策略
vector的实现技术不是简单的用户每新增一个数据,内部扩充一个数据空间,填充数据、销毁空间,因为这种逻辑带来的时间成本很大,事实上vector空间配置策略依赖于一种未雨绸缪的机制,也即随着元素插入,vector会申请更大的预留的空间,把旧的数据拷贝到新空间上,供给用户使用。测试代码:
1
2
3
4
5
6
7
8void test(){
vector<int> v;
for(int i=0;i<=16;i++)
{
v.push_back(i); //压栈,尾部操作,对应的是pop_back
cout<<"容量:"<<v.capacity()<<"使用空间:"<<v.size()<<endl;
}
}
容量:1使用空间:1 容量:2使用空间:2 容量:4使用空间:3 容量:4使用空间:4 容量:8使用空间:5 容量:8使用空间:6 容量:8使用空间:7 容量:8使用空间:8 容量:16使用空间:9 容量:16使用空间:10 容量:16使用空间:11 容量:16使用空间:12 容量:16使用空间:13 容量:16使用空间:14 容量:16使用空间:15 容量:16使用空间:16 容量:32使用空间:17
可以看出,申请的空间大小是依次递增的。
2. vector的构造函数
数组赋值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/***********************************
v(array,array+n),将迭代器的首部到末尾元素赋值给vector容器
vector<int> v={1,2,3,4,5};
vector<int>{1,2,3,4,5};
return {} //返回空数组的两种方式
return vector<int>()
***********************************/
void test(){
int array[]={100,200,300,400,500};
vector <int>v(array,array+sizeof(array)/sizeof(array[0]));//注意这个范围是前闭后开
for(int i=0;i<v.size();i++){
cout<<v[i]<<endl;
}
}
//输出100,200,300,400,500按元素个数赋值
1
2
3
4
5
6
7
8
9
10
11/***********************************
vector <int>v(10,666)
v.assign(10,666) //均表示把10个666元素赋值给vector
***********************************/
void test(){
vector <int> v(10,555);//构造赋值,10个555
//v.assign(10,666); //assign赋值,10个666
for(vector<int>::iterator it=v.begin();it<v.end();it++){ //迭代器iterator遍历(可以看成指针),效果同for i循环
cout<<*it<<endl; //解引用,打印迭代器对应的数据
}
}vector同类赋值 也即operator=:
1 | v2=v1; |
3. 交换两个vector容器的值和容量大小
swap交换两个vector容器的数据,其容量也会发生对应的变化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//v2.swap(v1) at寻值,与[]区别是其有异常处理机制
void test(){
vector<int> v1(10,666);//v1是10个666
vector<int> v2(4,555);//v2是4个555
v2.swap(v1);//交换v1、v2数据
for(vector<int>::iterator it=v1.begin();it<v1.end();it++){
cout<<*it<<"\t";
}
cout<<"v1交换后容量:"<<v1.capacity();
puts("");
for(vector<int>::iterator it=v2.begin();it<v2.end();it++){
cout<<*it<<"\t";
}
cout<<"v2交换后容量:"<<v2.capacity();
}
4. vector容器数据存取操作
注意front和begin区别,前者代表索引值,后者是指针:效果上v.front()=(v.begin()),v.back()=(v.end()-1)
1
2
3
4
5
6
7
8
9//at(int idx) at寻值,与[]区别是其有异常处理机制
//operator[] 中括号寻值
//front 最开始的元素
//back 最后的数据元素
void test(){
int array[]={100,200,300,400,500};
vector <int>v(array,array+sizeof(array)/sizeof(array[0]));//注意这个范围是前闭后开
cout<<v.front()<<v.back()<<v.at(3)<<v[3]<<*(v.begin())<<*(v.end()-1);
}
5. vector容器大小操作
resize和reserve都用于指定容量大小,但是效果有所区别:
当指定容量大于当前的数据个数时,resize会为空余的空间执行初始化,int类型默认元素为0填充,char使用空字符填充,可以指定填充元素,实际使用量会扩充为指定的容量大小、容量也会适当大于或等于指定容量大小;reserve则只改变容量大小,不会改变实际使用的大小,也不会执行数据填充和初始化。
当指定容量小于当前数据个数,resize的容量不会改变,实际使用量变成指定容量大小,多余的元素会被省略;而reserve不会生效,容量、实际容量、元素等都不会改变。
1 | //long unsigned int size() 实际大小、元素个数 |
6. vector容器插入和删除操作
1 | //insert(const_iterator pos,data_t Elem); 迭代器位置插入元素 |
7. 容器相关算法
vector容器是基于数组实现的,在头文件<algorithm>和<numeric>也为vector容器内置了一些算法,例如打印数据、排序等,可以在vector、dequeue等容器进行使用。
1. 遍历操作迭代对象:for_each
内部实现:传入参数为first、last为容器的迭代器,指向头和尾,传入函数fn(也即对当前迭代对象进行操作)
1
2
3
4
5
6
7
8
9template<class InputIterator, class Function>
Function for_each(InputIterator first, InputIterator last, Function fn)
{
while (first!=last) {
fn (*first);
++first;
}
return fn; // or, since C++11: return move(fn);
}
example:遍历并且打印vector容器的元素: 1
2
3
4
5
6
7
8void PrintInfo(int i){ //迭代器对象是int类型,所以是int
cout<<i<<'\t';
}
void test(){
int array[]={1,3,2,4,0,8,1,2 };
vector<int> v(array,array+sizeof(array)/sizeof(array[0]));
for_each(v.begin(),v.end(),PrintInfo); //for_each属于algorithm库,而不是vector容器的类函数
}//1 3 2 4 0 8 1 2
- 排序算法sort
sort默认将int类型从小到大进行排序,策略参数为less
()(已省略) 此外sort也支持加入自己的策略函数,对非int类型的元素进行排序。1
2
3
4
5
6void test(){
int array[]={1,3,2,4,0,8,1,2 };
vector<int> v(array,array+sizeof(array)/sizeof(array[0]));
sort(v.begin(),v.end()); //从小到大排序
for_each(v.begin(),v.end(),PrintInfo); //for_each是一个全局函数,属于algorithm库,而不是vector容器
}//0 1 1 2 2 3 4 8
注意如果自定义函数是成员函数,必须是静态成员函数,因为非静态成员函数隐式地需要一个指向类对象实例(this指针)的参数,但是sort函数不提供这个对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Solution {
public:
static bool Mycmp(pair<int,int>p1,pair<int,int>p2){ //sort方法函数必须是非成员函数或者静态成员函数
return p1.second>p2.second;
}
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int,int>m1;
for(int i=0;i<nums.size();i++){
m1[nums[i]]++;
}
vector<pair<int,int>>temp;
for(const pair<int,int>&pair:m1){
temp.push_back(pair);
}
sort(temp.begin(),temp.end(),Mycmp);
vector<int>result;
for(int i=0;i<k;i++){
result.push_back(temp[i].first);
}
return result;
}
};
deque容器
deque容器类似是一种双端数组结构,能够同时在头部和尾部进行插入删除,弥补了vector容器头部操作时开销过大的问题,但deque的元素访问速度不及vector,这与它的内部实现有关。
1. deque内存管理策略
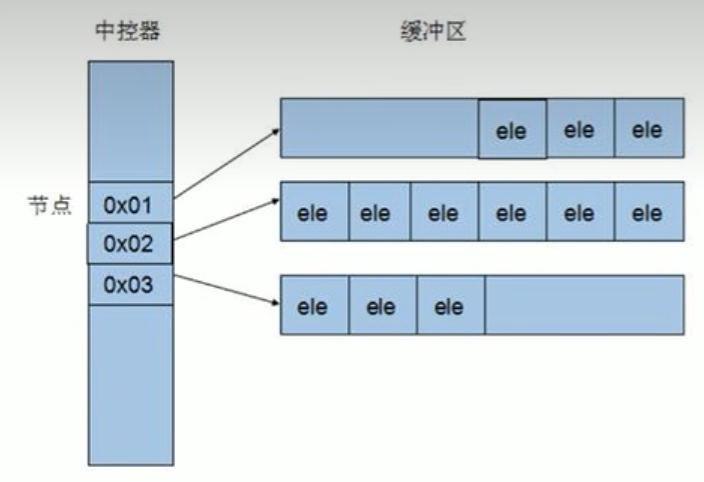
deque内部空间管理分成中控器和缓冲区,中控器存储的是缓冲区地址,缓冲区存放数据元素,当元素个数占满当前缓冲区时,中控器会开辟一个新的缓冲区,并且将地址放到中控器的前面或者后面进行管理,这样使得deque像使用一块连续内存空间一样,同样支持随机访问。但因为访问元素涉及到访问中控器的内容,再进行索引,因此访问元素效率低于vector。
2. deque的构造函数
与vector完全相同 1
2
3
4
5
6
7
8//deque<int> deq; //默认构造
//deque(iterator_begin,iterator_end); //开始结束迭代器
//deque(int num,data_t Elem); //num个Elem元素
//deque(const deque &deq); //拷贝构造
注:如果iterator使用const修饰,iterator对象*it就不能用于修改元素了(也即只读)
3. deque赋值操作
和vector类似 1
2
3
4
5
6
7
8
9//operator=
//assign(iterator_begin,iterator_end);
//assign(int num,data_t Elem)
deque<int> d1;
d1.assign(10,100);
deque<int> d2;
d2=d1;
d2.assign(d1.begin(),d1.end());
4. deque大小操作
deque比vector缺少了容量capacity概念,因为deque的容量可以任意向上向下扩充,没有容量大小限制的概念。
1
2
3
4//deque.empty() 判断容器是否为空
//deque.size() 容器元素个数
//deque.resize(int num) 指定容器大小,如果num大于原来的元素个数,则使用默认值填充;小于则删除多余元素
//deque.resize(int num,data_t Elem) 指定使用Elem进行填充,其他同上
5. deque插入和删除操作
1 | //push_back(data_t Elem) 容器尾部插入 |
6. deque索引操作
同vector 1
2
3
4//at(int idx)
//operator[]
//front()
//back()
stack容器
栈结构,即一种单端结构,只允许在栈顶操作和访问元素,没有遍历元素的操作(只有栈顶元素是可见的);此外该容器还提供了判断是否空栈、计算栈中元素个数的接口;由于该结构简单,所有接口函数如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//构造与赋值
stack<T> stk;
stack(const stack &stk);
stack& operator=(const stack &stk);
//入栈与出栈
push(Elem);
pop(); //弹出栈顶元素,void返回
//访问栈顶元素
top() ; //返回元素
//大小操作:
empty(); //为空返回true
size();
queue容器
队列结构,是简单的先进先出FIFO结构,一端用于入队,一端用于出队,同栈结构类似,只有队首和队尾元素是可见的,因此队列也没有遍历操作。接口如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//构造与赋值
queue<T> que;
queue(const queue&que)
queue& operator=(const queue &stk);
//入队与出队
push(Elem); //对队尾入队
pop();//队头出队,返回对头元素
//访问
back(); //返回队尾元素
front(); //返回队头元素
//大小操作
empty(); //队列是否为空
size(); //队列元素个数
list容器
STL中list是基于双向循环链表实现的,结点中含有前驱指针和后继指针,最后元素的后继指针指向表头,表头的前驱指针指向末尾结点。此外,list容器的迭代器不是随机访问迭代器,而是一种只支持前移和后移的双向迭代器。
list容器继承了链表结构的优点,即动态分配空间,不会造成内存浪费或者溢出;插入删除的时间复杂度小,不需改动大量的元素;此外list容器有一个重要的性质,也即插入和删除元素操作不会导致迭代器失效,而vector中是会的(因为插入删除可能导致空间销毁或者移动)。对应的,list容器的缺点是链表结构不支持随机存储访问,访问速度较慢,指针域也耗费了存储空间。
1. list容器构造函数
1 | //list<data_t> list //默认构造 |
2. list容器赋值与交换
1 | //assign(iterator_begin,iterator_end) |
3. list容器大小操作
1 | //size() |
4. list容器插入和删除
1 | //push_back(data_t Elem) 容器尾部插入 |
5. list数据存储
因为list是基于链表的结构,因此数据存取不再支持随机存储访问,也即中括号重载和at()不受支持。
1
2
3
4
5
6
7
8
9
10
11//front()
//back()
//支持双向访问,如
list<int>::iterator it=L1.begin();
it++; //支持
it--; //支持
//以下是不支持的写法,因为这也算随机访问:
//it=it+1; NO
//it=it+3; No
6. list算法
注意不支持随机存储访问的容器的sort函数不是一个全局函数,而是使用对象内部支持的成员函数进行的。
1
2
3
4
5
6//reverse(); //链表元素反转
//sort(); //小到大排序
//sort(L1.begin(),L1.end()); 这个函数来自<algorithm>,在vector、deque是成立的,在list等链式结构不成立
//L1.sort() 成员函数,list中成立
set容器
set和下一节要介绍的map都是基于红黑树或哈希表结构的容器,主要区别在于set是单值存储,map是键值对存储,set往往被用于描述一种集合结构,在集合中,数据的排序往往是不重要的,只需要判断该值是否存储在集合中,复杂时用于描述集合间的运算,如交集、并集、差集等。std中不同的set类型如下:
| 映射 | 底层实现 | 值是否有序 | 值是否可以重复 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 不可重复 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 可重复 | O(log n) | O(log n) |
| std::unordered_set | 哈希表 | 无序 | 不可重复 | O(1) | O(1) |
1. 构造与赋值
1 | /*********************************** |
2. 大小与交换
1 | /*********************************** |
3. 插入与删除
1 | /*********************************** |
4. 查找与统计
1 | /*********************************** |
5. 排序
默认存入set的数据是有序的,对int类型来说默认是从小到大,如果需要修改规则,使用仿函数进行修改,这里给出了内置数据类型(int),和自定义数据类型的效果代码:
1 | //对int进行从大到小排序 |
1 | //对自定义数据类型使用自定义规则进行排序 |
map容器
map容器是一种键值对结构,所以元素以键(key)和值(value)的方式存在,C++底层map容器具有三种形式,底层实现和特点不尽相同:
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | O(log n) | O(log n) |
| std::multimap | 红黑树 | key有序 | key可重复 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | O(1) | O(1) |
1. 构造与赋值
1 | /*********************************** |
2. 大小与交换
1 | /*********************************** |
3. 插入和删除
由于map的底层是红黑树或者哈希表,因此不能直接修改键(key),因为这样会破坏数据的结构,只能使用插入和删除的方式,而对于键对应的值(Value)是可以任意修改的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/***********************************
//插入
insert(Elem) 键值对插入
###unordered_map的插入:返回pair类型,first代表插入迭代器,bool代表是否插入成功(重复key不会成功)
pair<unordered_set<int,int>::iterator,bool>pos = m1.insert(make_pair(key,value));
### multimap只会返回迭代器,因为重复插入总是成功的。
//修改值
operator[]
//删除
clear() 清空容器
erase(pos_iterator)
erase(beg_iterator,end_iterator)
erase(key)
************************************/
//插入
m.insert(pair<int,int>(1,10))
m.insert(make_pair(1,10)); //无需声明类型
m.insert(map<int,int>::value_type(1,10));
m[3]=30;//插入key为3,值为30,少用于插入,多用于修改值
//删除
m.erase(m.begin()); //删除迭代器数据
m.erase(m.begin(),m.end()); //删除迭代器区间数据
m.erase(3); //删除key=3的键值对
4. 查找和统计
1 | /*********************************** |
5. 排序
map默认是按键值从小到大进行排序的,也支持自定义规则进行排序,自定义通过仿函数实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23//仿函数类或者结构体
class MyCompare{
public:
bool operator()(int x,int y) const{ //重载括号运算符函数
return x>y;
}
};
int main(){
map<int,int,MyCompare> m; //定义时需要声明相关仿函数类或结构体
m.insert(pair<int,int>(1,10));
m.insert(pair<int,int>(3,10));
m.insert(pair<int,int>(2,20));
m.insert(pair<int,int>(4,30));
//仿函数按自定义规则键值从大到小打印
for(map<int,int,MyCompare>::iterator it=m.begin();it!=m.end();it++){
cout<<"key="<<(*it).first<<"value="<<(*it).second<<endl;
}
}
