
Stanford CS144 For Computer Network(三):Lab1 Stitching substrings into a byte stream
Lab1 Stitching substrings into a byte stream
Lab1实验手册: https://vixbob.github.io/cs144-web-page/assignments/lab1.pdf(2021 Fall)
部分实验目的和内容摘抄自手册。
在Lab0的Warm up实验,我们完成了一些小实验,它们来自应用层的协议,例如过时的telnet协议,邮箱发送的smtp协议等,通过coding,完成了两个简单设计,包括简单的TCP的socket传输,以及实现一个deque的读写缓冲区;
进入Lab1——Lab4,我们将逐步实现一个TCP协议:Lab1的任务是实现一个流重组器;互联网TCP下层的所有协议,例如IP、以太网协议等均不会提供可靠的传输服务,可靠传输服务依靠TCP服务实现。数据报的传输是一种分组转发,如何将切片数据报重组成一个完整、无误的数据报,是TCP协议要实现的重要依靠。
实验目的
实现一个类,这个类就是实现流重组的类,初始定义如下,为了直观,删除了所有注释并改写中文注释如下:
1
2
3
4
5
6
7
8
9
10
11
12
13class StreamReassembler {
private:
ByteStream _output; //输出的重组字节流
size_t _capacity; //字节的最大容量
public:
StreamReassembler(const size_t capacity); //构造函数
void push_substring(const std::string &data, const uint64_t index, const bool eof); //根据接收data、index、eof信息重组字节流
const ByteStream &stream_out() const { return _output; } //返回只读字节流,并且不会更改成员变量
ByteStream &stream_out() { return _output; } //返回可读写字节流
size_t unassembled_bytes() const; //返回未重组的字节数
bool empty() const; //判断是否所有字符已经重组(未重组字节数为0)
};
根据手册,这里的_capacity由两部分组成,其一是已经重组完成、但未被读走字节,其二是接收了,但未被重组的字节数据。如图所示:
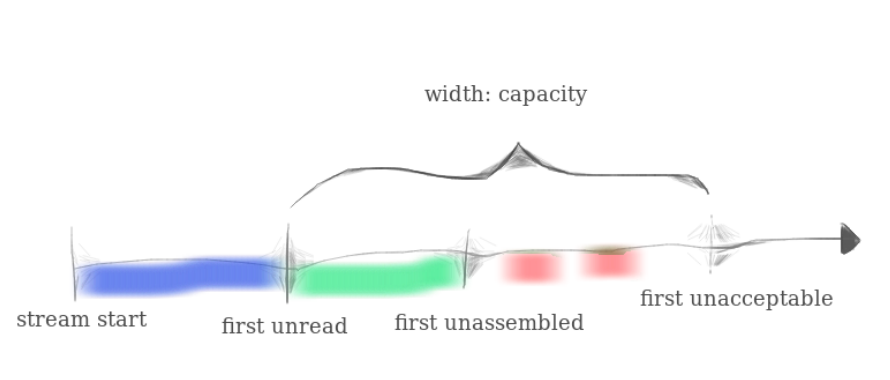 因此要完善的就是,考虑接收到一个data,并且知道data头的index(每次的index可能是乱序的),如何将数据整理成有序的字节流并且输出到output。
因此要完善的就是,考虑接收到一个data,并且知道data头的index(每次的index可能是乱序的),如何将数据整理成有序的字节流并且输出到output。
具体实现
正如实现描述所言,具体代码是非常自由的,应该注意一些实现方法细节:
- 理解索引index与data.size():这里的index应该是有一点迷惑的,例如将index看成真的索引值,代表每一个数据报分片的索引值,例如1、2、3号分片下分别有若干substring,此时需要讨论不同分片的交叠情况(见2)。第二种方法,实际上在计算机网络的分组重组,index代表是是一种片偏移量,例如index 0带来了30字节数据,那么下一次的index就是index 30,意味着每个分片的data一个char字符都是一个index,也完全可以按照处理单个数据的方法接收index。
- 如何表示暂存的缓冲区:需要保存的数据包括数据字符、数据索引;首先想到的应该是map结构,字符到达时插入暂存区,直接插入,等待到来的整个data装入了,或者输出的缓冲区已满,将暂存结构输出到output;有序的map意义并不大,因为结果最终需要输出到output,因此哈希表可以节省部分查找性能;从算法题目知道,哈希表也可以退化成特殊的数组。
哈希表方法,见代码: 1
2
3
4
5
6
7
8
9
10
11
12
13class StreamReassembler {
private:
// Your code here -- add private members as necessary.
ByteStream _output; //!< The reassembled in-order byte stream
size_t _capacity; //!< The maximum number of bytes
//here are user's definition
std::unordered_map<size_t,char>_unassembled; //暂存未组装结构
size_t _nidx; //已组装字节的下一个索引/第一个未组装索引
size_t _unassembled_cnt; //未组装字节数
size_t _eofidx; //最后一个分片索引
public:
......
1 | StreamReassembler::StreamReassembler(const size_t capacity) : //构造函数 |
验证: 1
2
3cd build&&make clean
make
make check_lab1
结果,如果更换成数组时间会更短,但还是ac了: 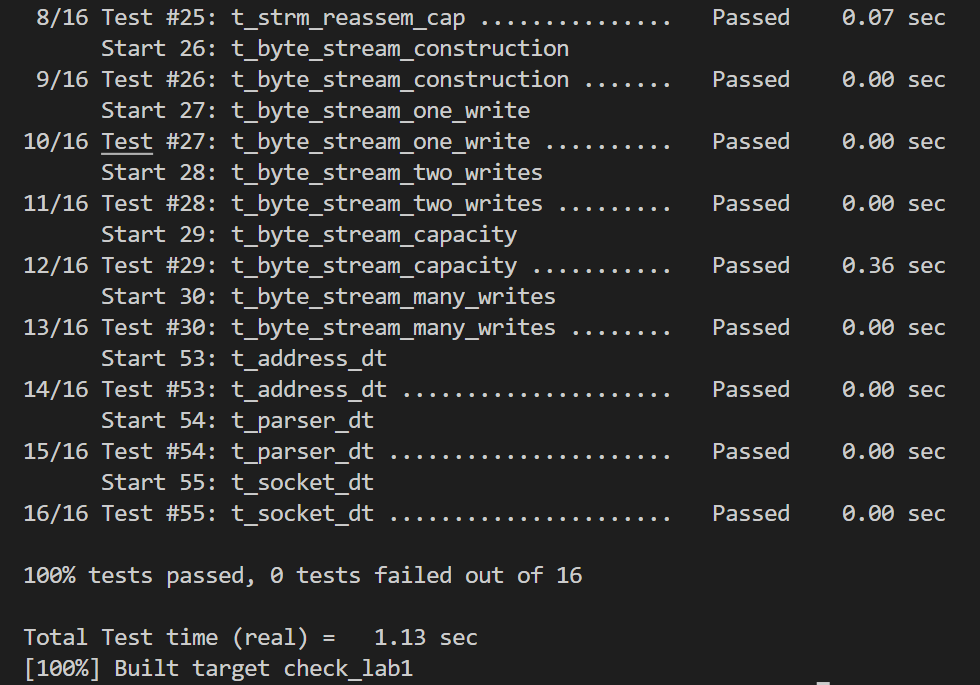
完整commit参考:Lab1 Done
总结
没有遇到奇怪的测试情况,因此也没有深入研究测试是怎么写的。要注意的是这里异常的index包含几种情况,例如出现重复的index(但重复字符是相同的,不会产生信息冲突)、或者暂存完发现了不连续index(未遇到eofidx就找不到_nidx了),这里一定要break掉处理,因为一定要保证暂存区元素是唯一、且有序的。这些是TCP常见的故障,还有一些情况可能没有考虑,这里仅追求易懂的代码表述。等做到后面可能还得修改这部分。
